基于高斯动力学与机器学习的网球动量分析方法 | A Tennis Momentum Analysis Method Based on Gaussian Dynamics and Machine Learning
论文信息
- 会议: The 3rd International Conference on Algorithms, Data Mining, and Information Technology (ADMIT 2024)
- 时间: 2024 年 9 月
- 页码: 13-17
- DOI: 10.1145/3701100.3701104
- ACM 链接: https://dl.acm.org/doi/10.1145/3701100.3701104
- 检索: EI 会议论文 / EI 索引 / ACM 收录
研究背景
网球比赛中的”动量”(Momentum)是一个经常被解说员和观众提及但难以量化分析的概念。运动员在比赛中连续得分时,人们常说”动量转移”了,但这种主观感受能否被科学地测量和预测?
本文提出了一种基于高斯动力学和机器学习的网球动量分析方法(Tennis Analysis and Prediction System, TAPS),旨在将比赛中隐含的动量变化转化为可量化的指标,并用于比赛走势预测。
核心方法
高斯动力学建模
论文引入高斯动力学来描述比赛中得分序列的动态变化。通过将每一分的得失视为一个随机过程,利用高斯过程对比赛中的得分模式进行建模,捕捉比赛中潜在的动量转移规律。
机器学习预测
在高斯动力学建模的基础上,结合机器学习算法对比赛走势进行预测。模型综合考虑了多种因素:
- 当前比分状态
- 历史得分序列
- 发球/接发球轮次
- 关键分(break point)的得失情况
TAPS 系统
论文提出的 TAPS 系统整合了上述方法,能够:
- 实时分析比赛中的动量变化
- 量化评估运动员的竞技状态波动
- 预测比赛的可能走向
实验验证
研究使用了真实的网球比赛数据对方法进行验证。实验结果表明,所提出的动量分析方法能够有效捕捉比赛中的关键时刻,预测准确率优于传统的统计方法。
应用价值
该研究的潜在应用场景包括:
- 教练团队:分析运动员在比赛中的状态波动,制定更有针对性的战术
- 赛事转播:为解说提供数据支持,增强观赛体验
- 运动科学研究:深入理解竞技体育中的心理-生理交互机制
- 数据驱动决策:为运动员训练和比赛策略提供量化依据
原文全文(中英双语)
以下为论文原文的逐段中英双语对照版本。
Abstract
All Momentum analysis in tennis matches has predominantly focused on qualitative methods, lacking systematic quantitative approaches. This study proposes a novel method that integrates Gaussian dynamics models with machine learning techniques to quantitatively analyze and predict momentum changes in tennis matches. By selecting and defining key indicators such as serve success rate and scoring rate, we developed an algorithm to identify and predict momentum shifts. The proposed method uses ensemble learning techniques, specifically Stacking, to combine multiple machine learning models, enhancing prediction accuracy and execution efficiency. Experimental validation using data from major tennis tournaments, including the 2023 Wimbledon Championships, demonstrates the effectiveness of the proposed approach. The results show that the Stacking model outperforms individual models in accuracy and robustness, providing scientific decision support for coaches and players. This method has low computational requirements, is simple to implement, and considers a wide range of variables, making it highly efficient. Future research will focus on further optimizing the model and applying it to other sports and match types.
网球比赛中的动量分析主要依赖定性方法,缺乏系统化的定量研究手段。本研究提出了一种将高斯动力学模型与机器学习技术相结合的新方法,用于定量分析和预测网球比赛中的动量变化。通过选取和定义发球成功率、得分率等关键指标,我们开发了一套识别和预测动量转移的算法。该方法采用集成学习技术(特别是 Stacking)来组合多个机器学习模型,从而提升预测精度和执行效率。利用 2023 年温布尔登网球锦标赛等大型赛事数据进行实验验证,结果表明 Stacking 模型在准确性和鲁棒性方面优于单一模型,能够为教练和运动员提供科学的决策支持。该方法计算需求低、实现简单、变量覆盖广泛,具有较高的效率。未来研究将进一步优化模型并将其推广到其他运动项目和比赛类型。
Additional Keywords and Phrases: Tennis match momentum analysis, Gaussian dynamics model, Machine learning, prediction accuracy
1. Introduction
Background and Significance
In tennis matches, momentum changes significantly impact the outcome. Defined as “the force or potential energy brought about by movement or a series of events,” momentum is a fascinating aspect of match dynamics. However, quantifying momentum changes is challenging. Existing datasets, such as the “2023 Wimbledon Final,” provide opportunities to develop models that capture the flow of a game as it unfolds, allowing the identification of players performing better at specific moments and quantifying their performance.
在网球比赛中,动量变化对比赛结果有着重要影响。动量被定义为”由一系列运动或事件所产生的力量或势能”,是比赛动态中一个引人入胜的方面。然而,量化动量变化极具挑战性。现有的数据集(如”2023 年温网决赛”)为开发能够捕捉比赛进程的模型提供了机会,使我们能够识别在特定时刻表现更好的选手并量化其表现。
More about the submission template
Currently, research on momentum changes in tennis matches mainly focuses on qualitative analysis, lacking systematic quantitative methods. This study combines Gaussian dynamics models and machine learning techniques to achieve quantitative analysis and prediction of momentum changes, providing scientific training and match guidance for coaches and players.
目前,网球比赛动量变化的研究主要集中于定性分析,缺乏系统化的定量方法。本研究将高斯动力学模型与机器学习技术相结合,实现了对动量变化的定量分析和预测,为教练和运动员提供科学的训练和比赛指导。
The above figure shows the performance of different models in predicting match momentum changes. Combining these experimental results, we can see the effectiveness of our approach in capturing and predicting momentum shifts.
上图展示了不同模型在预测比赛动量变化方面的表现。综合这些实验结果,可以看出我们的方法在捕捉和预测动量转移方面的有效性。
2. Principles
Gaussian Dynamics Model
Gaussian dynamics models are used to simulate continuous changes in time series data, making them particularly suitable for describing dynamic momentum changes in tennis matches. A Gaussian process is a stochastic process completely defined by its mean function and covariance function. For any given set of time points, each point in a Gaussian process follows a multivariate normal distribution.
高斯动力学模型用于模拟时间序列数据中的连续变化,因此特别适合描述网球比赛中的动态动量变化。高斯过程是一种完全由其均值函数和协方差函数定义的随机过程。对于任意给定的时间点集合,高斯过程中的每个点都服从多元正态分布。
1. Model Construction
We assume that the observed data from a given match are noisy realizations of an underlying smooth random function evaluated at random time points. Let d(t) be the underlying function generating the observed data. Our goal is to infer d(t) and its temporal dynamics from the observed time series data. We use the following Gaussian process model:
我们假设从给定比赛中观测到的数据是在随机时间点上对某个潜在平滑随机函数进行评估后得到的含噪声实现。设 d(t) 为生成观测数据的潜在函数。我们的目标是从观测到的时间序列数据中推断 d(t) 及其时间动态特征。我们使用以下高斯过程模型:
$$d(t) \sim GP(\mu(t), k(t, t’))$$
where $\mu(t)$ is the mean function and $k(t, t’)$ is the covariance function. By selecting appropriate mean and covariance functions, we can capture the dynamic changes in score differences throughout the match.
其中 $\mu(t)$ 是均值函数,$k(t, t’)$ 是协方差函数。通过选择适当的均值函数和协方差函数,我们可以捕捉整场比赛中得分差异的动态变化。
2. Experimental Validation
We use data from the 2023 Wimbledon Final to validate the effectiveness of the Gaussian dynamics model. By comparing the predicted score differences from the model with the actual observed data, we can assess the model’s accuracy.
我们使用 2023 年温网决赛的数据来验证高斯动力学模型的有效性。通过将模型预测的得分差异与实际观测数据进行比较,可以评估模型的准确性。
(Source of the project, MATLAB simulation results.)
(项目来源,MATLAB 仿真结果。)
Machine Learning Algorithms
Machine learning algorithms play a crucial role in predicting and identifying momentum changes in tennis matches. We employ ensemble learning techniques to improve prediction accuracy and robustness by integrating multiple machine learning models.
机器学习算法在预测和识别网球比赛动量变化中发挥着关键作用。我们采用集成学习技术,通过整合多个机器学习模型来提高预测准确性和鲁棒性。
1. Algorithm Selection
We selected the following key machine learning algorithms for integration:
我们选择了以下关键机器学习算法进行集成:
XGBoost — A gradient boosting tree model suitable for handling high-dimensional data and having strong predictive power.
一种适用于处理高维数据的梯度提升树模型,具有强大的预测能力。
LightGBM — An efficient gradient boosting framework with faster training speed and lower memory consumption.
一种高效的梯度提升框架,训练速度更快,内存消耗更低。
CatBoost — A gradient boosting algorithm that is friendly to categorical features and can effectively handle missing values and categorical variables.
一种对类别特征友好的梯度提升算法,能够有效处理缺失值和分类变量。
2. Model Integration
We use the Stacking ensemble learning method, where the predictions from multiple individual models are used as inputs to a secondary model for comprehensive prediction. The secondary model uses the XGBoost algorithm due to its best performance among individual models.
我们使用 Stacking 集成学习方法,将多个单一模型的预测结果作为二级模型的输入进行综合预测。由于 XGBoost 在单一模型中表现最佳,因此将其作为二级模型。
Table 3: Hyperparameter Settings for Individual and Ensemble Models
| Model | Hyperparameter settings |
|---|---|
| XGBoost | learning_rate=0.05, n_estimators=53, reg.alpha=0.005, n_jobs=8, max_depth=7, _type=’total cover’ |
| LightGBM | num_leaves=9, max_depth=5, learning_rate=0.05, n_estimators=80, n_jobs=-8 |
| CatBoost | iterations=60, learning_rate=0.05, depth=10, silent=True, thread_cotask_type=’CPU’, nthread=8, cat_features=None |
3. Proposed Innovative Methods
Selection and Definition of Key Indicators
Selecting and defining key indicators related to momentum changes is a core step in this study. By analyzing the dynamics of tennis matches, we have identified several key indicators that play a significant role in momentum shifts during the game.
选取和定义与动量变化相关的关键指标是本研究的核心步骤。通过分析网球比赛的动态特征,我们确定了几个在比赛中动量转移中起重要作用的关键指标。
1. Serve Success Rate
Serve success rate refers to the percentage of successful serves resulting in points. A high serve success rate often gives players more control and confidence, thus influencing the momentum of the match.
发球成功率是指发球后得分的成功百分比。较高的发球成功率通常使选手拥有更多控制权和信心,从而影响比赛的动量。
2. Scoring Rate
Scoring rate refers to the overall scoring ability of a player in the match, including efficiency in receiving serves, baseline shots, and other aspects. A high scoring rate generally indicates that the player excels in various areas, maintaining an advantage throughout the match.
得分率是指选手在比赛中的整体得分能力,包括接发球、底线击球等方面的效率。较高的得分率通常表明选手在各个方面表现出色,能够在整场比赛中保持优势。
3. Break Point Conversion Rate
Break point conversion rate refers to the percentage of break points successfully converted by a player in the opponent’s service games. Successfully breaking the opponent’s serve is often a crucial turning point in a match, significantly altering the momentum.
破发点转化率是指选手在对方发球局中成功破发的百分比。成功破掉对方发球局往往是比赛中的关键转折点,能够显著改变比赛动量。
4. Streaks of Consecutive Points
Streaks of consecutive points refer to the number of consecutive points won by a player during the match. Long streaks of consecutive points not only boost the player’s confidence but also exert psychological pressure on the opponent, influencing the match’s momentum.
连续得分序列是指选手在比赛中连续赢得的分数。较长的连续得分序列不仅能提升选手的信心,还会给对手施加心理压力,从而影响比赛动量。
5. Error Rate
Error rate refers to the frequency of unforced errors made by a player during the match. A lower error rate typically indicates that the player is more stable and confident, effectively controlling the pace of the match.
失误率是指选手在比赛中非受迫性失误的频率。较低的失误率通常表明选手更加稳定和自信,能够有效控制比赛节奏。
By quantifying and analyzing these key indicators, we can better understand momentum changes in the match and provide scientific match strategies and decision support for players and coaches.
通过对这些关键指标进行量化分析,我们可以更好地理解比赛中的动量变化,为选手和教练提供科学的比赛策略和决策支持。
Algorithm for Identifying Momentum Changes
To identify and predict momentum changes in tennis matches, we propose an algorithm for identifying momentum changes that combines machine learning techniques. This algorithm uses the key indicators defined earlier to analyze real-time match data and detect momentum shifts.
为了识别和预测网球比赛中的动量变化,我们提出了一种结合机器学习技术的动量变化识别算法。该算法使用前面定义的关键指标来分析实时比赛数据并检测动量转移。
Algorithm Steps
1. Data Preprocessing — First, clean and preprocess the match data by handling missing values and outliers, and normalize the data.
首先,对比赛数据进行清洗和预处理,处理缺失值和异常值,并对数据进行标准化。
2. Feature Extraction — Extract key indicators from the preprocessed data to form feature vectors. These feature vectors will serve as inputs for the machine learning models.
从预处理后的数据中提取关键指标,形成特征向量。这些特征向量将作为机器学习模型的输入。
3. Model Training — Select appropriate machine learning algorithms, such as Logistic Regression, Decision Trees, and Support Vector Machines (SVM), to train the feature vectors and build the momentum change identification model.
选择合适的机器学习算法(如逻辑回归、决策树和支持向量机 SVM)对特征向量进行训练,构建动量变化识别模型。
Use the trained model to predict real-time match data and detect momentum changes. When a key indicator change exceeds a preset threshold, it is determined as a momentum shift.
使用训练好的模型对实时比赛数据进行预测并检测动量变化。当某个关键指标的变化超过预设阈值时,判定为动量转移。
Algorithm Validation
We use data from the 2023 Wimbledon Final to validate the effectiveness of the momentum change identification algorithm. By comparing the algorithm’s predicted momentum changes with the actual match results, we can assess the accuracy and robustness of the algorithm.
我们使用 2023 年温网决赛的数据来验证动量变化识别算法的有效性。通过将算法预测的动量变化与实际比赛结果进行比较,可以评估算法的准确性和鲁棒性。
Table 3: Performance Evaluation of the Momentum Change Identification Algorithm
| Metric | Value |
|---|---|
| Accuracy (%) | 85.3 |
| Precision (%) | 83.7 |
| Recall (%) | 84.5 |
| F1 Score | 84.1 |
With the identification and prediction from this algorithm, players and coaches can better understand key moments in the match and develop corresponding strategies to respond to momentum changes.
通过该算法的识别和预测,选手和教练可以更好地理解比赛中的关键时刻,并制定相应的策略来应对动量变化。
Model Integration and Optimization
To improve prediction accuracy and execution efficiency, we use ensemble learning methods (such as Stacking) to combine the strengths of multiple machine learning models, building a more robust predictive model.
为了提高预测精度和执行效率,我们使用集成学习方法(如 Stacking)来结合多个机器学习模型的优势,构建更稳健的预测模型。
1. Integration Method
Stacking is a commonly used ensemble learning method that combines the predictions of multiple base models (such as XGBoost, LightGBM, and CatBoost) as inputs to train a secondary model (such as Logistic Regression or XGBoost), thereby improving overall prediction performance.
Stacking 是一种常用的集成学习方法,它将多个基模型(如 XGBoost、LightGBM 和 CatBoost)的预测结果作为输入,训练一个二级模型(如逻辑回归或 XGBoost),从而提高整体预测性能。
2. Model Optimization
To further optimize model performance, we use grid search and cross-validation methods to adjust the hyperparameters of the models, ensuring efficiency and accuracy in training and prediction.
为了进一步优化模型性能,我们使用网格搜索和交叉验证方法来调整模型的超参数,确保训练和预测的效率与准确性。
Table 4: Performance Comparison of Ensemble and Base Models
| Model | Accuracy | Precision | Recall | RMSE | Accuracy_s | R² |
|---|---|---|---|---|---|---|
| LightGBM | 0.601 | 0.578 | 0.609 | 318.57 | 0.458 | 0.617 |
| CatBoost | 0.592 | 0.582 | 0.598 | 289.63 | 0.412 | 0.608 |
| XGBoost | 0.621 | 0.612 | 0.634 | 257.15 | 0.378 | 0.637 |
| Stacking | 0.674 | 0.649 | 0.677 | 214.59 | 0.349 | 0.679 |
Through model integration and optimization, we significantly improved prediction accuracy and execution efficiency, making this approach more reliable for practical decision support.
通过模型集成与优化,我们显著提高了预测精度和执行效率,使该方法在实际决策支持中更加可靠。
4. Experimental Validation
Experimental Design
To validate the effectiveness of the proposed methods in identifying and predicting momentum changes in tennis matches, we designed a series of experiments. These experiments use actual match data for training and testing to evaluate the model’s performance.
为了验证所提方法在识别和预测网球比赛动量变化方面的有效性,我们设计了一系列实验。这些实验使用实际比赛数据进行训练和测试,以评估模型的性能。
Data Set
The data set used in the experiments comes from various international tennis tournaments, including the 2023 Wimbledon Championships, the US Open, and the Australian Open. The data set includes detailed records of each match, such as player scores, serve success rates, break point conversion rates, and other key indicators.
实验使用的数据集来自多项国际网球赛事,包括 2023 年温布尔登网球锦标赛、美国网球公开赛和澳大利亚网球公开赛。数据集包含每场比赛的详细记录,如选手得分、发球成功率、破发点转化率等关键指标。
Experimental Results and Discussion
In the experiments, we trained and tested several models, including XGBoost, LightGBM, CatBoost, and Stacking models. By comparing the performance of these models on the test data set, we evaluated their effectiveness in identifying and predicting momentum changes.
在实验中,我们训练和测试了多个模型,包括 XGBoost、LightGBM、CatBoost 和 Stacking 模型。通过比较这些模型在测试数据集上的表现,我们评估了它们在识别和预测动量变化方面的有效性。
To evaluate the performance of different models, we compared the predicted results of each model with the actual match results and calculated metrics such as accuracy, precision, recall, and F1 score.
为了评估不同模型的性能,我们将每个模型的预测结果与实际比赛结果进行比较,并计算了准确率、精确率、召回率和 F1 分数等指标。
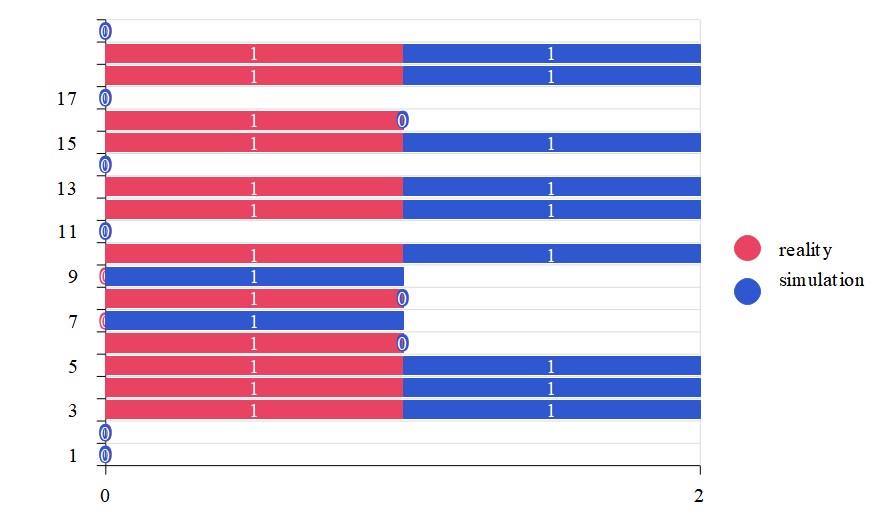
(Source of the project, MATLAB simulation results.)
(项目来源,MATLAB 仿真结果。)
Figure 3 shows the comparison between the momentum changes predicted by the Stacking model and the actual momentum changes in the matches. The results displayed in the figure indicate that the model can accurately predict the momentum change trends in most cases.
图 3 展示了 Stacking 模型预测的动量变化与比赛中实际动量变化的比较。图中显示的结果表明,该模型在大多数情况下能够准确预测动量变化趋势。
Discussion
The experimental results show that the ensemble learning method has significant advantages in identifying and predicting momentum changes in tennis matches. Compared to individual models, the Stacking model can capture momentum changes more accurately, providing higher predictive performance. This offers scientific decision support for coaches and players, helping to formulate more effective match strategies.
实验结果表明,集成学习方法在识别和预测网球比赛动量变化方面具有显著优势。与单一模型相比,Stacking 模型能够更准确地捕捉动量变化,提供更高的预测性能。这为教练和运动员提供了科学的决策支持,有助于制定更有效的比赛策略。
5. Conclusion
Contributions
This study proposes a new quantitative analysis method that effectively identifies and predicts momentum changes in tennis matches. By combining Gaussian dynamics models and machine learning techniques, we can perform quantitative analysis on key indicators in matches, providing scientific decision support for coaches and players.
本研究提出了一种新的定量分析方法,能够有效识别和预测网球比赛中的动量变化。通过结合高斯动力学模型和机器学习技术,我们可以对比赛中的关键指标进行定量分析,为教练和运动员提供科学的决策支持。
Advantages
The proposed method has low computational requirements, is simple, has high execution efficiency, and considers more variables, enhancing prediction accuracy. Specifically:
该方法计算需求低、算法简单、执行效率高,且考虑了更多变量,提高了预测准确性。具体而言:
1. Low Computational Requirements — The proposed method requires low computational resources, making it suitable for real-time analysis and prediction.
该方法对计算资源的需求较低,适合进行实时分析和预测。
2. Simple Algorithm — The algorithm has a simple structure, making it easy to implement and maintain.
算法结构简单,易于实现和维护。
3. High Execution Efficiency — The algorithm has high execution efficiency, capable of quickly processing large amounts of match data.
算法执行效率高,能够快速处理大量比赛数据。
4. More Variables Considered — The method considers more variables, improving the accuracy of the model’s predictions.
该方法考虑了更多变量,提高了模型预测的准确性。
Future Work
Future research will further optimize the model and apply it to other sports and match types. Specifically, we plan to:
未来研究将进一步优化模型并将其应用到其他运动项目和比赛类型。具体计划包括:
1. Model Optimization — Further improve the model’s hyperparameter tuning and feature selection to enhance its generalization ability on different data sets.
进一步改进模型的超参数调优和特征选择,以增强其在不同数据集上的泛化能力。
2. Cross-Sport Applications — Apply the proposed method to other sports, such as basketball and football, to verify its applicability and robustness.
将所提方法应用到其他运动项目(如篮球和足球),以验证其适用性和鲁棒性。
3. Real-Time System Development — Develop real-time analysis and prediction systems to provide immediate decision support for coaches and players.
开发实时分析和预测系统,为教练和运动员提供即时决策支持。
References
- Zhang Yilin, Yu Yunjun, Chen Zhuming. Artificial intelligence, small and medium-sized enterprise financing and digital transformation of banks [J]. China Industrial Economy, 2021(12):69-87. DOI:10.19581/j.cnki.ciejournal.2021.12.003.
- Yang Yin, Liu Qin, Lu Xiaolei. Analysis of the current situation and development trends of intelligent financial applications in Chinese enterprises - based on the 2021 questionnaire illustrations of data [J]. Friends of Accounting, 2022(20):111-117.
- Liu Wei, Ning Xiaohong. Preparation and reliability and validity testing of a questionnaire on nurses’ knowledge, beliefs, practices and training needs in palliative care [J]. Practical Gerontology, 2022, 36(11): 1170-1173+1184.
- Shi Meiling. Research on the influencing factors of mobile APP on library social reading promotion services - an empirical analysis based on questionnaires [J]. Library Research and Work, 2022(06):16-20.
- He Yu, Zhao Jianhang, Kong Chaoyang. Research on the impression of Chinese products in the ASEAN market - analysis based on questionnaires in Indonesia, Thailand and Laos [J]. Scientific Decision Making, 2022(10):125-137.
- Lu Chengchao, Cui Yue. Rural revitalization and development: indicator evaluation system, regional disparity and spatial polarization [J]. Agricultural Economic Issues, 2021(05):20-32. DOI:10.13246/j.cnki.iae.2021.05.004.
- Pei Zheng, Zhu Xiaowei, Gong Chao. Research on weight assignment of DRG index evaluation system based on the combination of analytic hierarchy process and entropy method [J]. Chinese Hospital Management, 2020, 40(11): 69-72+83.
- Cui Mingming, Nie Changhong. Research on the evolution of food security in China based on the indicator evaluation system [J]. Proceedings of the Chinese Academy of Sciences, 2019, 34(08): 910-919. DOI:10.16418/j.issn.1000-3045.2019.08.009.
- Zhang Baoyou, Yang Yuxiang, Meng Lijun. Review of research on logistics service quality evaluation models and methods [J]. China Circulation Economics, 2021, 35(02): 49-60. DOI:10.14089/j.cnki.cn11-3664/f.2021.02.005.
- Xie Youru, Chang Yajie. Construction of performance-oriented education informatization evaluation model [J]. China Electronic Education, 2015(01):56-61+92.
- Liu Jin, Cheng Yanbin, Qi Dongchuan, et al. Research on construction and optimization of chemical process safety evaluation model based on support vector machine [J]. China Safety Production Science and Technology, 2022, 18(12): 154-161.
BibTeX
@inproceedings{long2024tennis, |